
Scaleway Managed Inference
Offre de Managed Inference Service de Scaleway.
Prix : https://www.scaleway.com/en/pricing/deployment/
Product page : https://www.scaleway.com/en/inference/
Changelog : https://www.scaleway.com/en/docs/changelog/?product=managed-inference
Journaux liées à cette note :
Journal du mardi 25 février 2025 à 22:12
Un ami me demande :
Réponse courte : je pense qu'un NPU ne te sera d'aucune utilité pour exécuter un LLM de qualité sur ton laptop 😔.
Quand mon ami parle d'une « IA en local », je suppose qu'il souhaite exécuter un agent conversationnel qui exploite un LLM, du type ChatGPT, Claude.ai, LLaMa, DeepSeek, etc.
Sa motivation première est la confidentialité.
Cela fait depuis juin 2023 que je souhaite moi aussi self host un LLM, avant tout pour éviter le vendor locking, maitriser son coût et éviter la "la merdification des choses".
En juin 2024, je pensais moi aussi que les NPU étaient une solution technique pour self hosted un LLM. Mais depuis, j'ai compris que j'étais dans l'erreur.
Je trouve que ce commentaire résume aussi bien la fonction des NPU :
Also, people often mistake the reason for an NPU is "speed". That's not correct. The whole point of the NPU is rather to focus on low power consumption.
...
I have a sneaking suspicion that the real real reason for an NPU is marketing. "Oh look, NVDA is worth $3.3T - let's make sure we stick some AI stuff in our products too."
D'après ce que j'ai compris, voici ce que les NPU exécutent en local (ce qui inclut également la technologie Microsoft nommée Copilot) :
- L'accélération des modèles d'IA pour la reconnaissance vocale, la transcription en temps réel, et la traduction.
- Traitement plus rapide des images et vidéos pour des effets en direct (ex. flou d'arrière-plan, suppression du bruit audio).
- Réduction de la consommation électrique en exécutant certaines tâches IA en local, sans solliciter massivement le CPU/GPU.
Je pense que les fonctionnalités MS Windows Copilot qui utilisent des LLM sont exécutées sur des serveurs mutualisés avec de gros GPU.
Si j'ai bien compris, pour faire tourner efficacement un LLM en local, il est essentiel de disposer d'une grande quantité de RAM avec une bande passante élevée.
Par exemple :
- Une carte NVIDIA RTX 5090 avec 32Go de RAM (2700 €)
- Une carte NVIDIA RTX 3090 avec 24Go de RAM d'accasion (1000 €)
- Une Puce Apple M4 Max avec CPU 16 cœurs, GPU 40 cœurs et Neural Engine 16 cœurs 128 Go de mémoire unifiée (plus de 5000 €)
- Une Puce Apple M4 Pro avec CPU 12 cœurs, GPU 16 cœurs, Neural Engine 16 cœurs 64 Go de mémoire unifiée (2400 €)
Je ne suis pas disposé à investir une telle somme dans du matériel que je ne parviendrai probablement jamais à rentabiliser. À la place, il me semble plus raisonnable d'opter pour des Managed Inference Service tels que Replicate.com ou Scaleway Managed Inference.
Voici les tarifs de Scaleway Generative APIs :
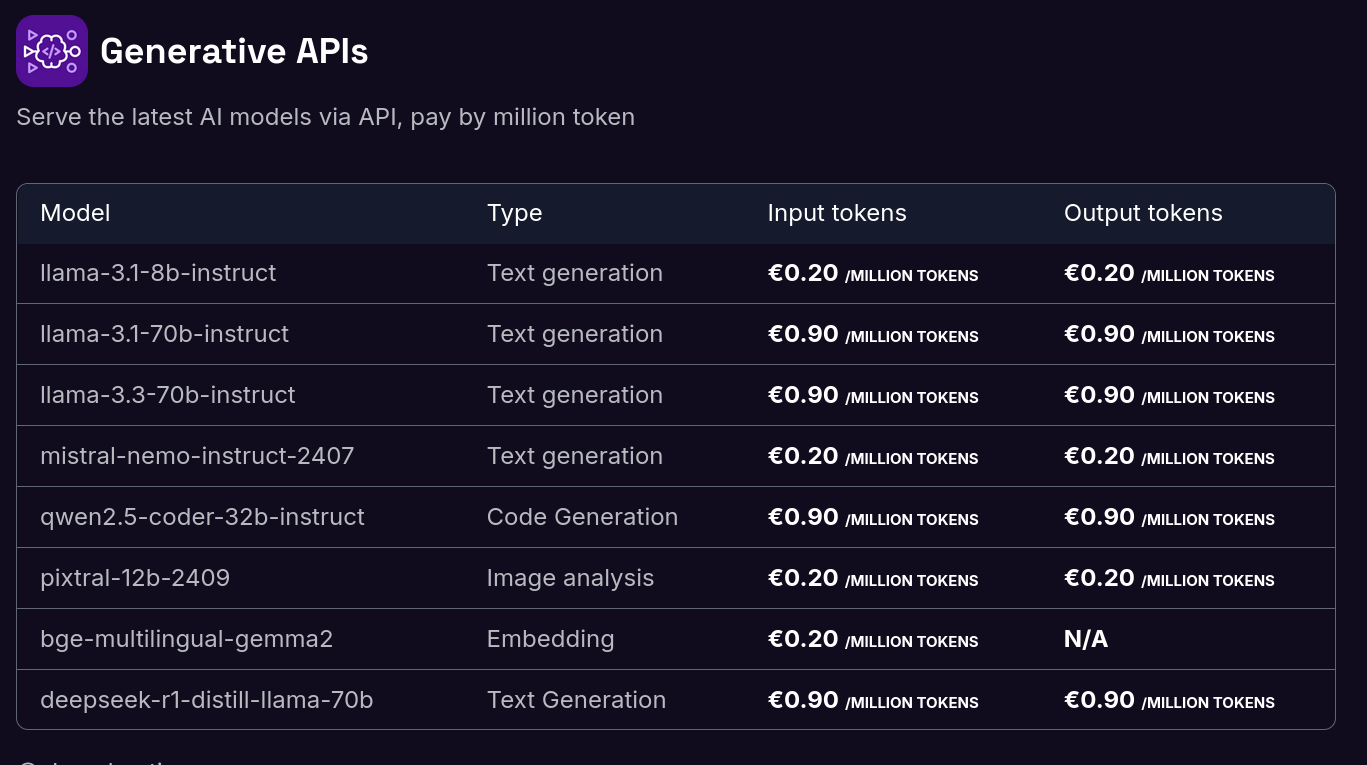
Il y a quelques semaines, j'ai connecté Open WebUI à l'API de Scaleway Managed Inference avec succès. Je pense que je vais utiliser cette solution sur le long terme.
Si je devais garantir une confidentialité absolue dans un cadre professionnel, je déploierais Ollama sur un serveur dédié équipé d'un GPU :
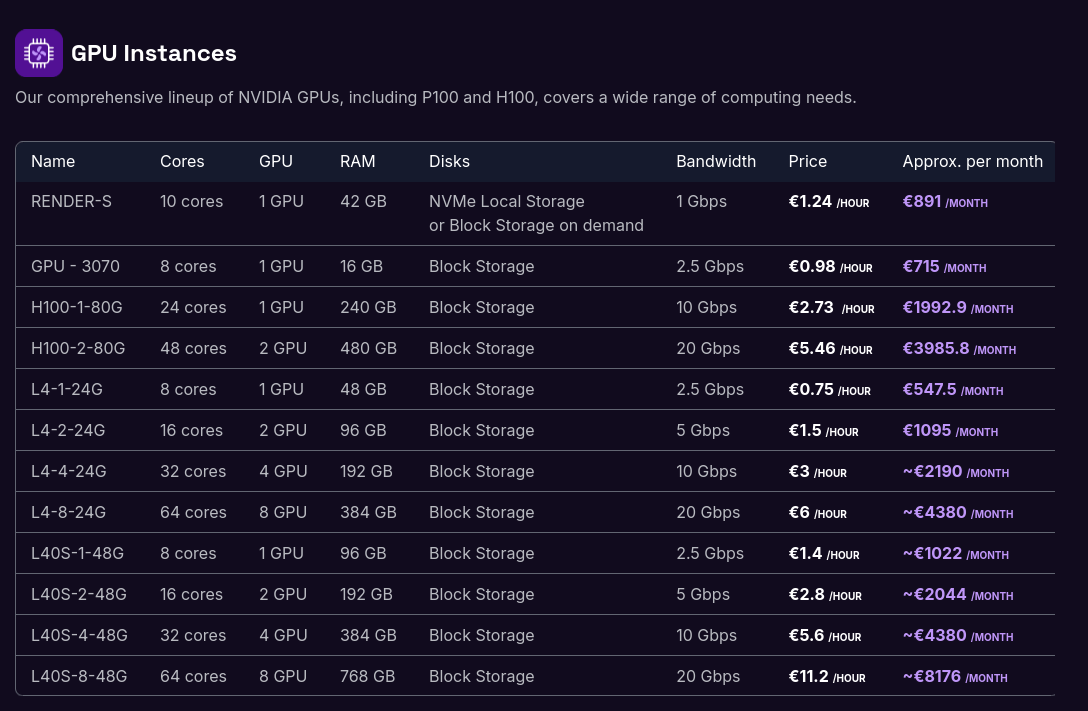
Journal du mardi 23 juillet 2024 à 15:54
#JaiDécouvert que Scaleway a déployé en public beta une offre d'Managed Inference Service : Scaleway Managed Inference.
Added : Managed Inference is available in Public Beta
Managed Inference lets you deploy generative AI models and answer prompts from European end-consumers securely. Now available in public beta! (from)
C'est une alternative à Replicate.com.
Models now support longer and better conversations :
- All models on catalog now support conversations to their full context window (e.g Mixtral-8x7b up to 32K tokens, Llama3 up to 8k tokens).
- Llama3 70B is now available in FP8 quantization, INT8 is deprecated.
- Llama3 8b is now available in FP8 quantization, BF16 remains default.
L'offre est beaucoup moins large que celle de Replicate mais c'est un bon début 🙂.
Tarif de l'offre de Scaleway :
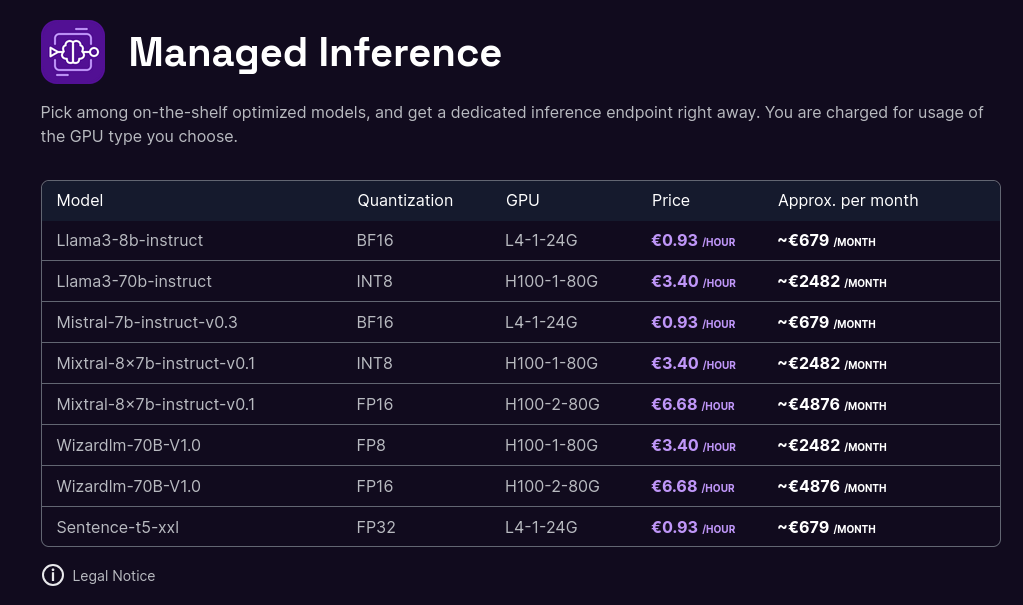
Tarif de l'offre de Replicate.com :
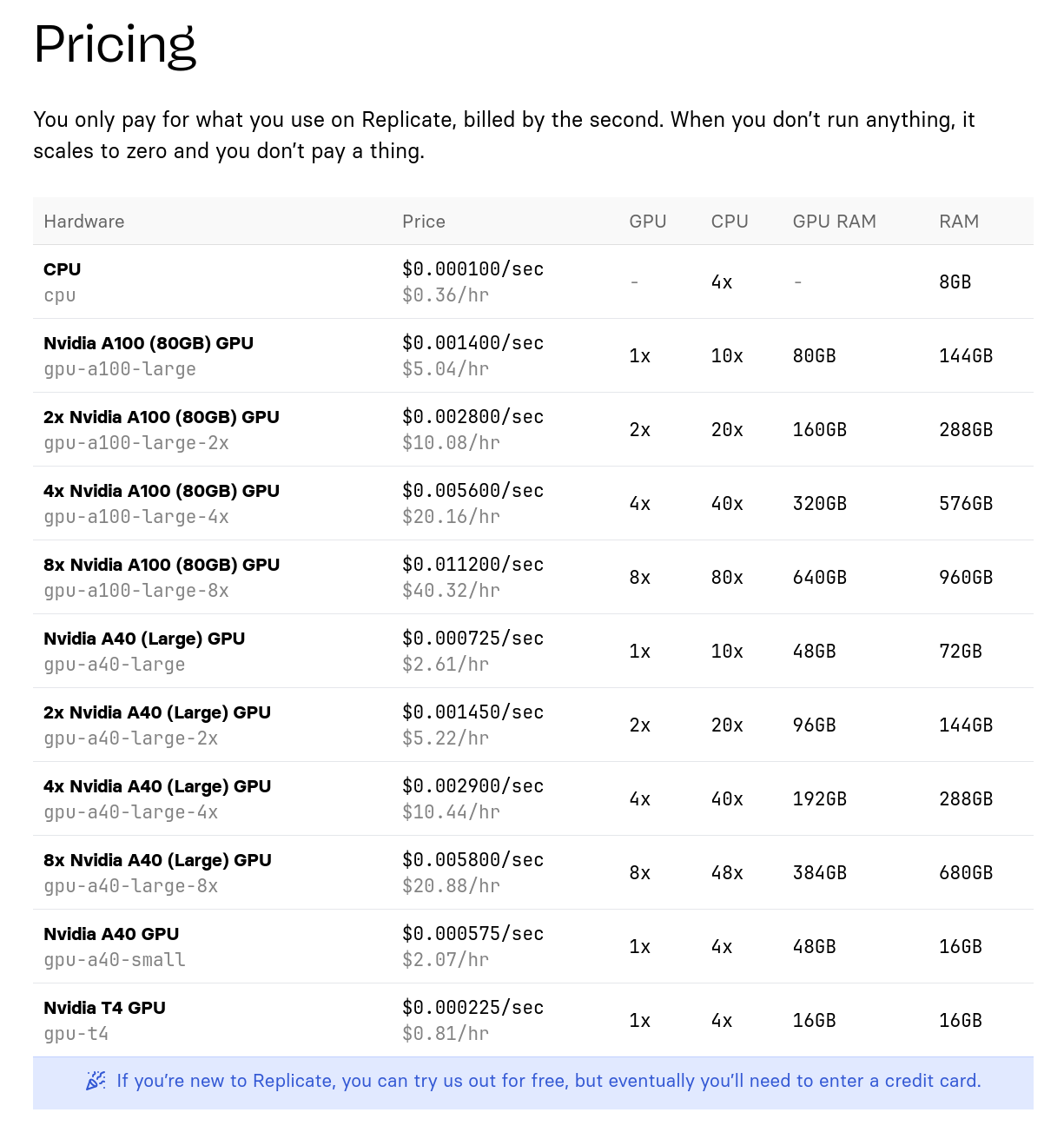
Bien que le matériel soit différent, j'essaie tout de même de faire une comparaison de prix :
- Scaleway : 0,93 € / heure pour une machine à 24Go de Ram GPU
- Replicate : 0,81 $ / heure pour une machine à 16GB de Ram GPU
Ensuite :
- Scaleway : 3,40 € / heure pour une machine à 80Go de Ram GPU
- Replicate : 5,04 € / heure pour une machine à 80Go de Ram GPU
Je précise, que je n'ai aucune idée si ma comparaison a du sens ou non.
Je n'ai pas creusé plus que cela le sujet.
Note en lien avec 2024-05-17_1257.